
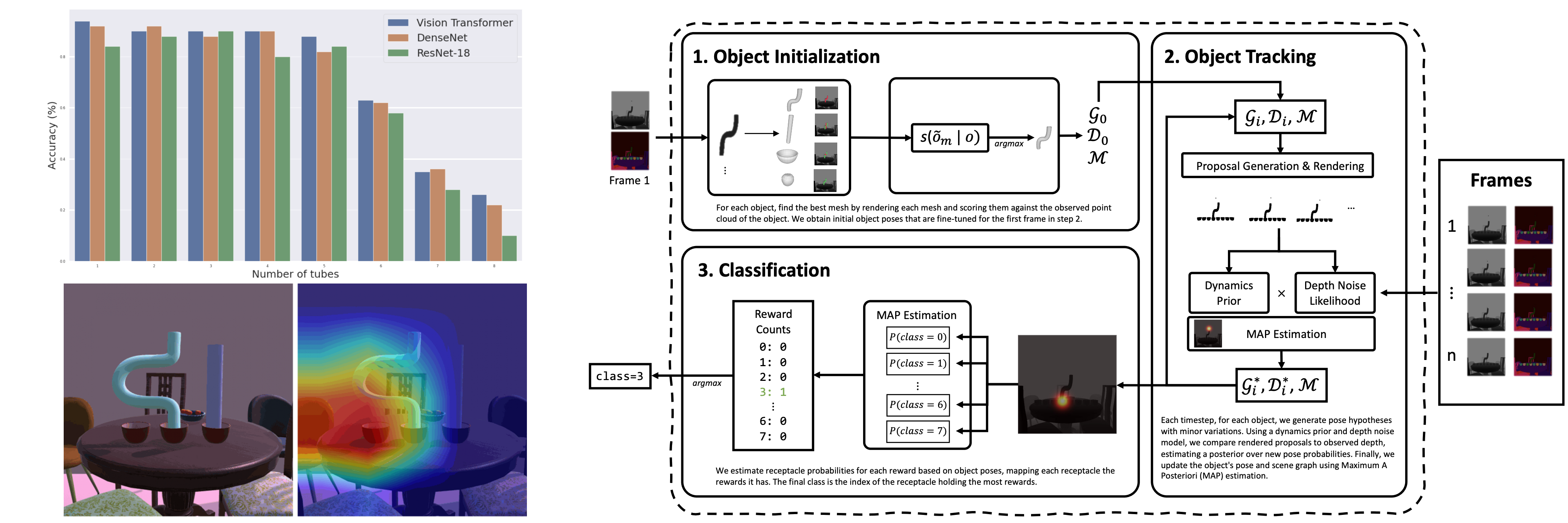
Humans have a wide range of cognitive capacities that make us adept at understanding our surroundings, making inferences even with minimal visual cues. Emulating this understanding in AI systems has various applications, from autonomous driving to virtual reality. Despite the proficiency demonstrated by deep neural networks, recent works have uncovered challenges in their abilities to encode prior physical knowledge, form visual concepts, and perform compositional reasoning. Inspired by this, we develop the Simulated Cognitive Tasks benchmark, a synthetic dataset and data generation tool, based on cognitive tests targeting intuitive physics understanding in primates. We evaluate recent deep learning models on this benchmark and identify challenges in understanding object permanence, quantities, and compositionality. Therefore, we propose a probabilistic generative model that leverages Bayesian inverse graphics to learn structured scene representations that facilitate learning new objects and tracking objects in dynamic scenes. Our evaluation suggests that structured representations and symbolic inference can cooperate with deep learning methods to interpret complex 3D scenes accurately. Overall, we contribute a new method for improving scene understanding in AI models and provide a benchmark for assessing the visual cognitive capacities of computational models.
Check out the project GitHub repository.
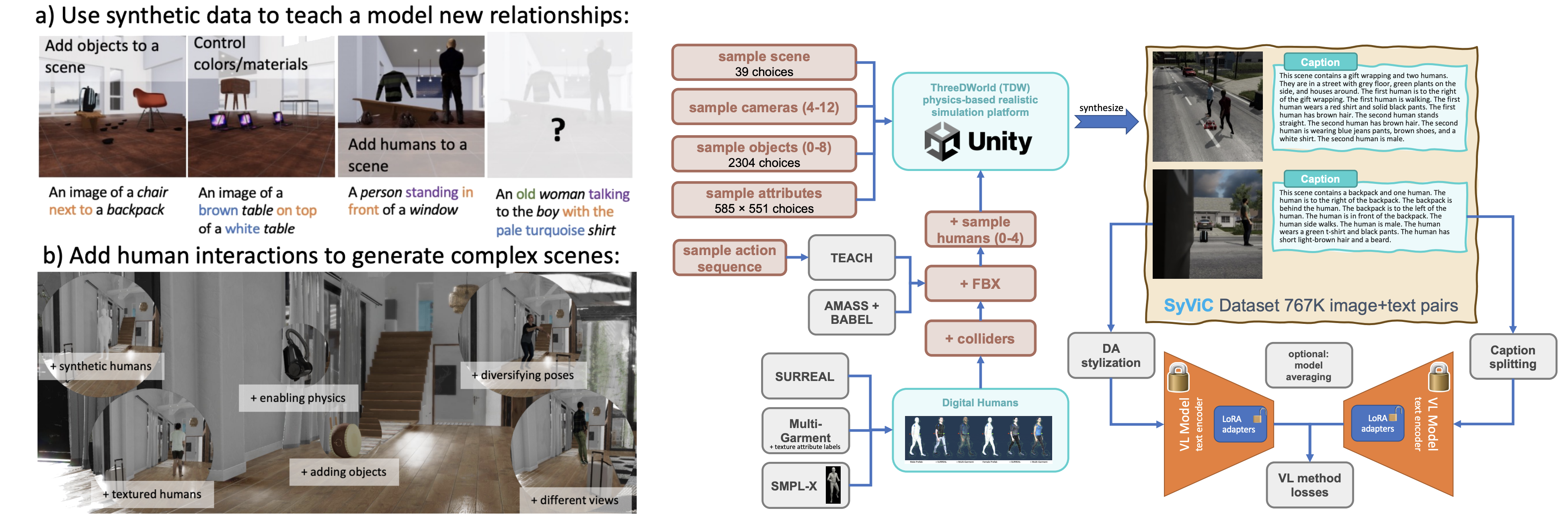
Large-scale pre-trained Vision & Language (VL) models have shown remarkable performance in many applications, enabling replacing a fixed set of supported classes with zero-shot open vocabulary reasoning over (almost arbitrary) natural language prompts. However, recent works have uncovered a fundamental weakness of these models. For example, their difficulty to understand Visual Language Concepts (VLC) that go 'beyond nouns' such as the meaning of non-object words (e.g., attributes, actions, relations, states, etc.), or difficulty in performing compositional reasoning such as understanding the significance of the order of the words in a sentence. In this work, we investigate to which extent purely synthetic data could be leveraged to teach these models to overcome such shortcomings without compromising their zero-shot capabilities. We contribute Synthetic Visual Concepts (SyViC) - a million-scale synthetic dataset and data generation codebase allowing to generate additional suitable data to improve VLC understanding and compositional reasoning of VL models. Additionally, we propose a general VL finetuning strategy for effectively leveraging SyViC towards achieving these improvements. Our extensive experiments and ablations on VL-Checklist, Winoground, and ARO benchmarks demonstrate that it is possible to adapt strong pre-trained VL models with synthetic data significantly enhancing their VLC understanding (e.g. by 9.9% on ARO and 4.3% on VL-Checklist) with under 1% drop in their zero-shot accuracy.
Check out the project page and paper.
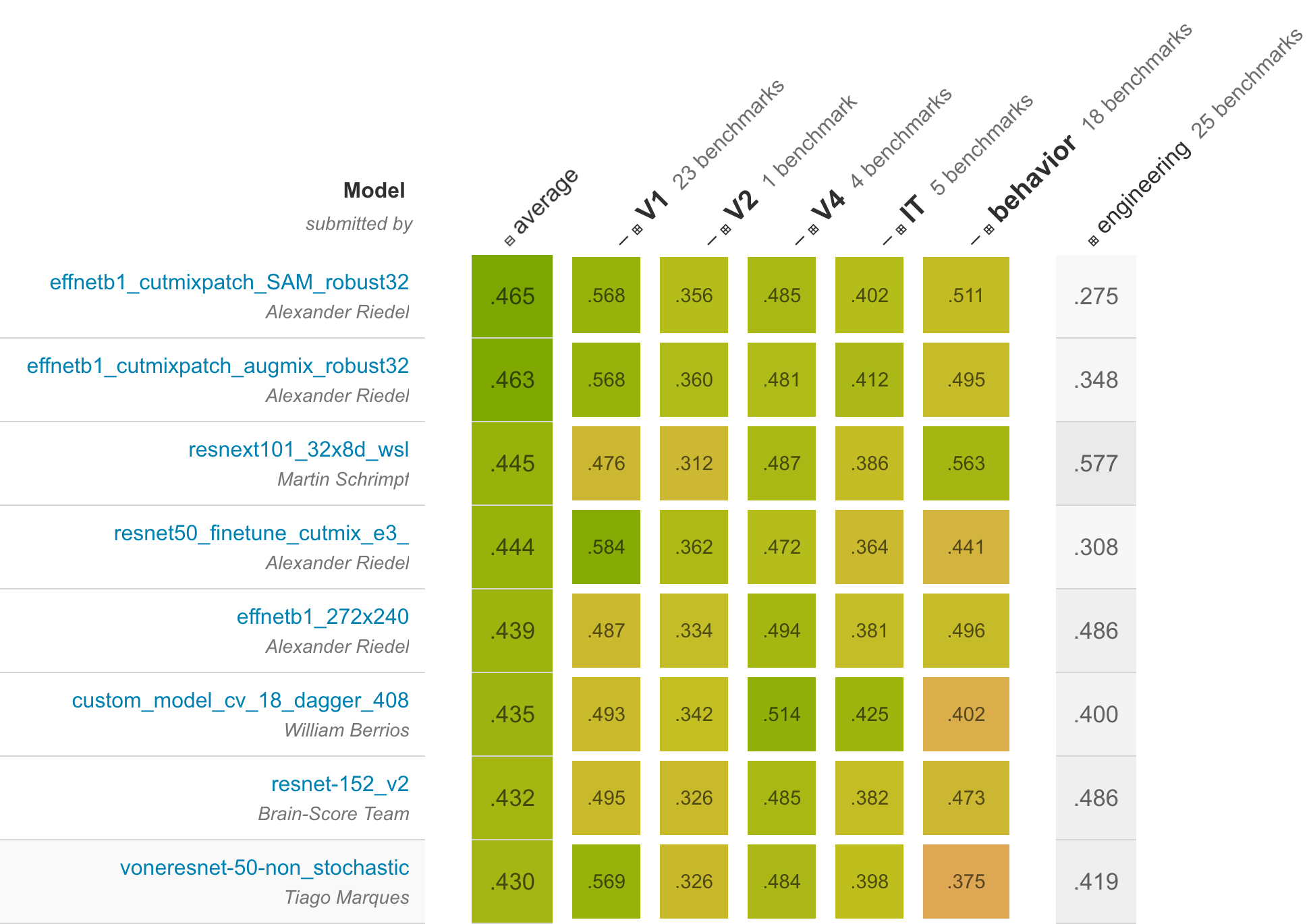
Brain-Score hypothesizes that the more similar the activations of neural networks are to human brain recordings, and the closer their behavior is to that of humans, the better they will perform. The platform facilitates this evaluation by providing a system infrastructure to implement models as artificial subjects and score them on a series of benchmarks. Accordingly, Brain-Score translates experimental data into benchmarks against which any model can be evaluated, and it allows for additional benchmark integration through a plugin management system.
Check out the project website and GitHub repository.
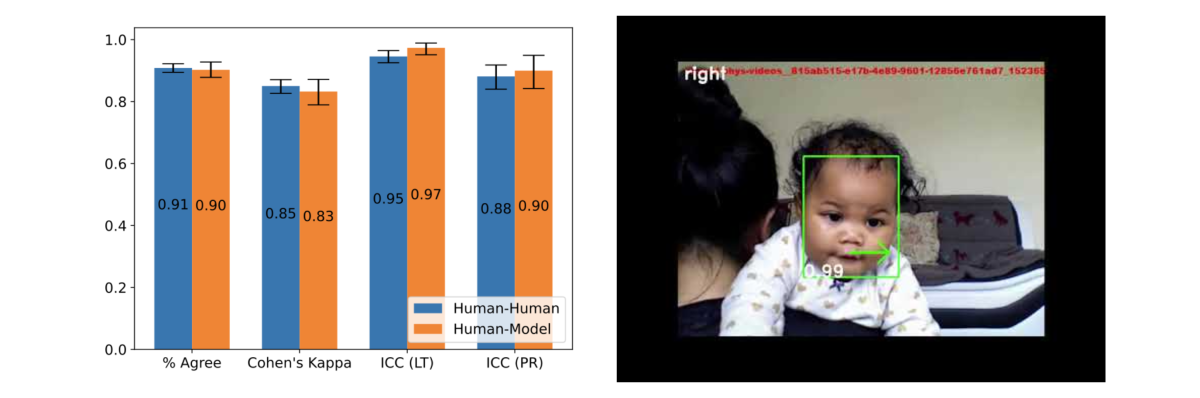
While machine learning has enhanced large-scale psychological research, analyzing infant and child looking behavior remains a manual task. iCatcher+ is a system for automated gaze annotation trained on varied datasets of children from 4 months to 3.5 years. It uses a series of machine learning models to identify the face of the child and estimate their looking direction, all fine-tuned to handle uncertainties in infant behavior. iCatcher+ achieves near human-like precision in identifying gaze patterns across different situations and demographics. This progress hints at potential full automation of online behavioral studies in children, facilitating developmental research on infants.
Check out the project GitHub repository.